COVID Sequencing Database
GENSAM — COVID Sequencing Data Platform
GENSAM started as a bare-bones portal built to secure further funding — something that worked on the happy path. When anything went wrong, labs had no way to know what had happened or what to do next. I redesigned it from scratch.
Client
The Public Health Agency of Sweden
Role
UX/UI Designer
Tools
Figma · Confluence · Jira
Domain
Life sciences · Public health
Team
Solo designer · Government tech stack
Insight
The core anxiety wasn't "what went wrong" — it was "did anything happen at all." A deposition could cross two labs and pass through a supercomputer, and there was nothing to tell anyone where it stood.
Action
Designed a deposition-first flow — collect all details and verify the SMiNet registry match before a single file is uploaded. Then a timeline to make every step legible, whether it's the originating lab or a different lab doing the actual upload.
Impact
Labs that had abandoned the platform came back. The SMiNet match problem was surfaced before it became irreversible. And for the first time, anyone involved in a deposition — regardless of which lab they were in — could see exactly where it stood.
The Problem
A national COVID sequencing platform had been built as a minimal proof of concept. It worked when everything went right. When something went wrong — a filename mismatch, a failed registry check, a file from the wrong lab — it failed silently and gave no one a path forward.
Background
An MVP built under urgency, now silently failing the labs that depended on it
GENSAM was Sweden's national platform for registering and tracking COVID genomic sequencing data. Around 10% of all positive COVID tests in Sweden were deposited and analysed through it — building a dataset that epidemiologists could use to track how mutations spread across time and geography.
The platform had been built quickly as an MVP to demonstrate something working — enough to secure further funding. On the happy path, it did. Anything off it — a failed upload, a filename mismatch, a failed registry check — either failed silently or left the lab with no way forward.
The result: data loss, labs emailing files as a workaround, and an admin burden that fell on senior scientists who had much better things to do.
My Role
Solo designer running research and design end-to-end on a constrained government tech stack
UX/UI Designer at LH+P. I ran research and discovery, redesigned the platform from the ground up, and worked directly with the engineering team on a constrained government tech stack. Same embedded team as SVEBar — I ran both projects in parallel.
Running two projects in parallel with the same agency team meant I understood the institutional context well. It also meant I had to be strict about where my time went.
Discovery
Interviews and working sessions across multiple regions — mapping the full deposition workflow from sample to confirmed upload
I ran interviews and working sessions with lab technicians across multiple Swedish regions. The goal was to understand the full deposition workflow — from receiving a positive test, to preparing sequencing files, to confirming that the result had landed in permanent storage and was accessible to the labs that needed it.
No error states, no status tracking, no way to update a submission once started. Labs had built workarounds: spreadsheets to track batches, phone calls to confirm receipt, re-submissions when in doubt.
Every deposition had to be matched against SMiNet — Sweden's infectious disease registry — before the sequencing result could be permanently stored. If a file failed after uploading and the SMiNet ID had already been spent, it couldn't be reused. The lab had to contact the agency to resolve it. That admin work fell on senior scientists who had much better things to do — and there weren't enough of them to keep up.
A lab in Stockholm might own a deposition but have a lab in another city do the actual sequencing and upload the files. The platform had no concept of a cross-lab handoff. There was no way to see where a deposition stood or who was responsible for the next step.
Some tests were sequenced from both sides of the genome, producing two files instead of one. The platform had one upload slot. There was also no mechanism for collecting deposition details before files were uploaded — so the system had no way to know whether to expect one file or two.
Baseline going in
Labs were emailing files instead of using the platform. The SMiNet ID problem was creating an admin bottleneck at the agency. And depositions that crossed lab boundaries had no visibility at all — nobody knew where they stood.
[ Research findings / workflow mapping — add photo or Figma export here ]
The Hard Part
A government stack that couldn't build everything users needed, and a trust problem requiring technical fixes design couldn't fully provide
The SMiNet ID couldn't be un-spent
Once an ID was consumed by a failed upload, it was gone. Design couldn't fix the backend — but it had to surface the match check before upload, not after. Getting that change scoped and prioritised was not straightforward.
Cross-lab depositions had no clear owner
When the lab that owned a deposition was different from the lab doing the upload, nobody had visibility. The design needed to make handoffs explicit — but the platform had no concept of a multi-lab deposition at all.
Deposition details had to come before files
To know whether to show a single or paired file upload, the system needed the sequencing technology selected first. Changing the flow so that the deposition form was filled in before any upload started was a constraint the engineering team had to agree to.
Government tech constraints
Some backend fixes that users genuinely needed weren't buildable in the current funding round. I had to design for what was actually buildable and document the rest clearly enough that it could be scoped in a future round.
How I Navigated It
The core design decision: make the user's progress visible instead of exposing system state
The insight that unlocked the design: instead of building better error states — which required significant backend work — I proposed a timeline-based mental model as the primary architecture. Making the user's progress visible was buildable within the current constraints, and it addressed the core anxiety directly: "did my submission actually go through?"
For Test ID matching, I proposed integrating it directly into the platform flow, eliminating the external spreadsheet dependency and removing a major failure point from the workflow.
For features that couldn't be built yet, I documented them in the product backlog with user research rationale — so the agency had a clear brief for the next funding round rather than a wishlist with no supporting evidence.
How Might We
Make every step of a deposition legible to whoever is responsible for it — whether that's the lab that owns it or a different lab doing the upload — and catch errors before they become permanent?
Design
Timeline-based submission flow, real error states for the first time, and Test ID matching built into the platform
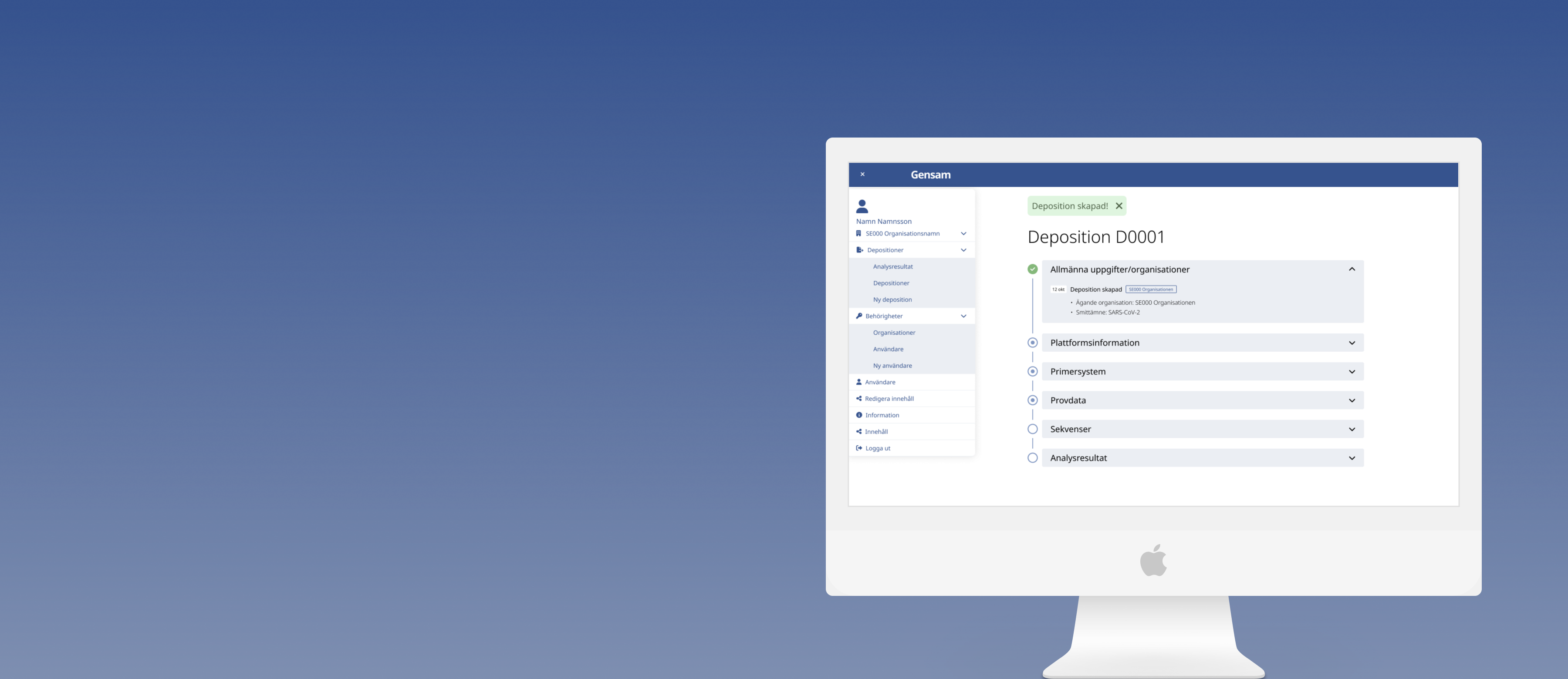
Once the flow was agreed, I designed the timeline view, the deposition-first upload form, error states, and the SMiNet validation as a connected system — each piece addressed a specific failure mode from research.
Every deposition shows its current state at a glance — initiated, files uploaded, SMiNet matched, sequencing in progress, result available. Legible to both the owning lab and any lab involved in the upload. The result appeared as a genome version code, visible to the labs once sequencing was complete.
First real error handling the platform had. Each error surfaces with specific guidance — including what to do if the SMiNet ID has already been consumed, so labs know immediately whether they need to contact the agency.
Deposition details — including which sequencing technology was used — are collected before any files are uploaded. The platform then presents the right form: one file slot for standard sequencing, two for paired-end. Eliminated the ambiguity about what was expected and prevented the file type mismatch errors that caused most silent failures.
The SMiNet registry match is surfaced at the deposition stage, before files are uploaded. Labs see immediately whether the ID will match — catching the most irreversible failure before it happens rather than after.
Depositions show their full history — initiated by which lab, files uploaded by which lab, current responsible party. For the first time, a lab in Stockholm could see the status of a deposition being fulfilled by a lab in another city.
[ Timeline view / hi-fi screens — add your Figma export here ]
Testing & Iterations
Low-fidelity walkthroughs targeting the three highest-anxiety moments in the submission workflow
Low-fidelity wireframes tested with 4 lab technicians across two sessions. Scenarios focused on the three highest-anxiety moments: submitting a batch, encountering an error mid-submission, and checking the status of a previous deposition.
Key validation: The timeline model was immediately intuitive. All four participants understood their position in the process without being prompted. Error visibility was described as "finally knowing what went wrong" by one participant who had previously experienced silent failures.
Findings informed two rounds of iteration before moving to high-fidelity: error state copy was rewritten to be more actionable, and timeline detail level was adjusted to match what users actually needed to see versus what felt like noise.
Results
Labs returned to the platform — and the email workaround that measured lost trust was eliminated
What I'd do differently
Push harder to get the SMiNet ID release mechanism built before shipping. The design surfaced the mismatch earlier, but a spent ID was still a dead end. One backend fix — letting the agency release a spent ID without manual intervention — would have closed the biggest remaining failure mode. I flagged it. I'd have made the case more formally with the research findings behind it.
Design System
New patterns for the timeline view and error state hierarchy — documented for agency engineering teams to build on independently
Built to Swedish public sector design standards. The timeline view, the deposition-first upload form, and the error state hierarchy were all new patterns — the standards didn't cover any of them. I documented each with rationale and handed them off to the agency engineering team.
The documentation included usage guidance, edge cases, and rationale — so the team could extend the patterns without needing a designer for every decision.
Help me improve this case study
Takes about 30 seconds — I read every response.
Are you here as a...
Was this case study relevant to what you were looking for?
What's missing or unclear? (optional)